Data Cloud
Customer Data Platform
A trusted data foundation for your business, built for customer relationships. Quickly access and easily action on centralized data in order to drive growth and increase customer lifetime value.


What can Marketers do with Data Cloud?
Centralizing data is just the first step, but it’s not enough. Data Cloud isn’t just about bringing data together, it’s about bringing entire organizations together around customers, enabling marketing to deliver more impactful campaigns. We make this possible by being natively built on CRM, designed for the full customer experience, and completely open and flexible.
Operational Customer Profile
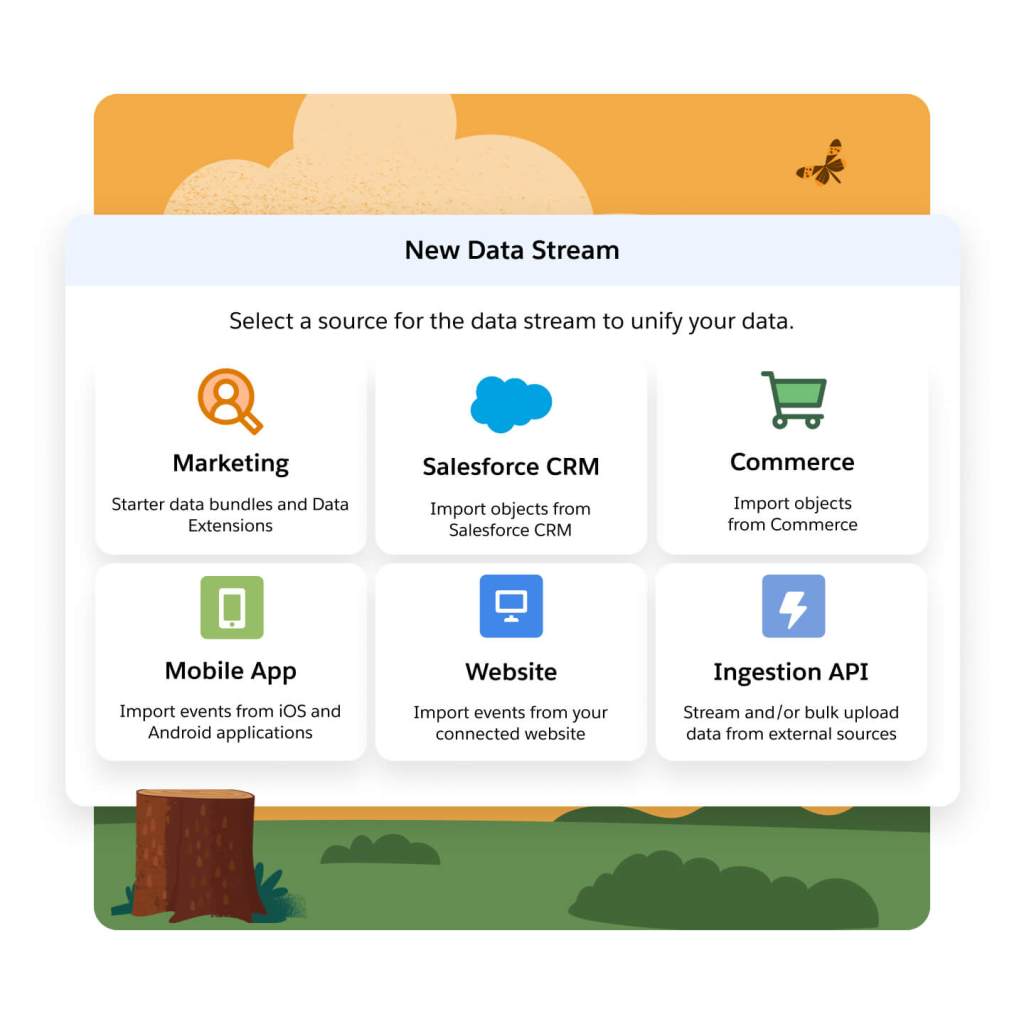
Prepare new data for seamless consumption by marketing teams and downstream systems (e.g., kick off a personalized journey in Marketing Cloud, update Contact record in Sales Cloud) using a click-and-drag interface to standardize and map incoming data to the data model in Data Cloud.
Unify and leverage non-CRM or third-party data (e.g., inventory, click data) without needing to physically move or copy it, using two-way data access between Salesforce and partners like Snowflake or Google BigQuery.

Reduce the amount of custom integrations and maintenance preventing marketing teams from using data in campaigns. Ingest and combine customer data with native connectivity to Salesforce apps (Marketing, Sales, Service, Commerce), prebuilt integrations to cloud storage like Amazon S3, and the ability to connect to any system with MuleSoft.
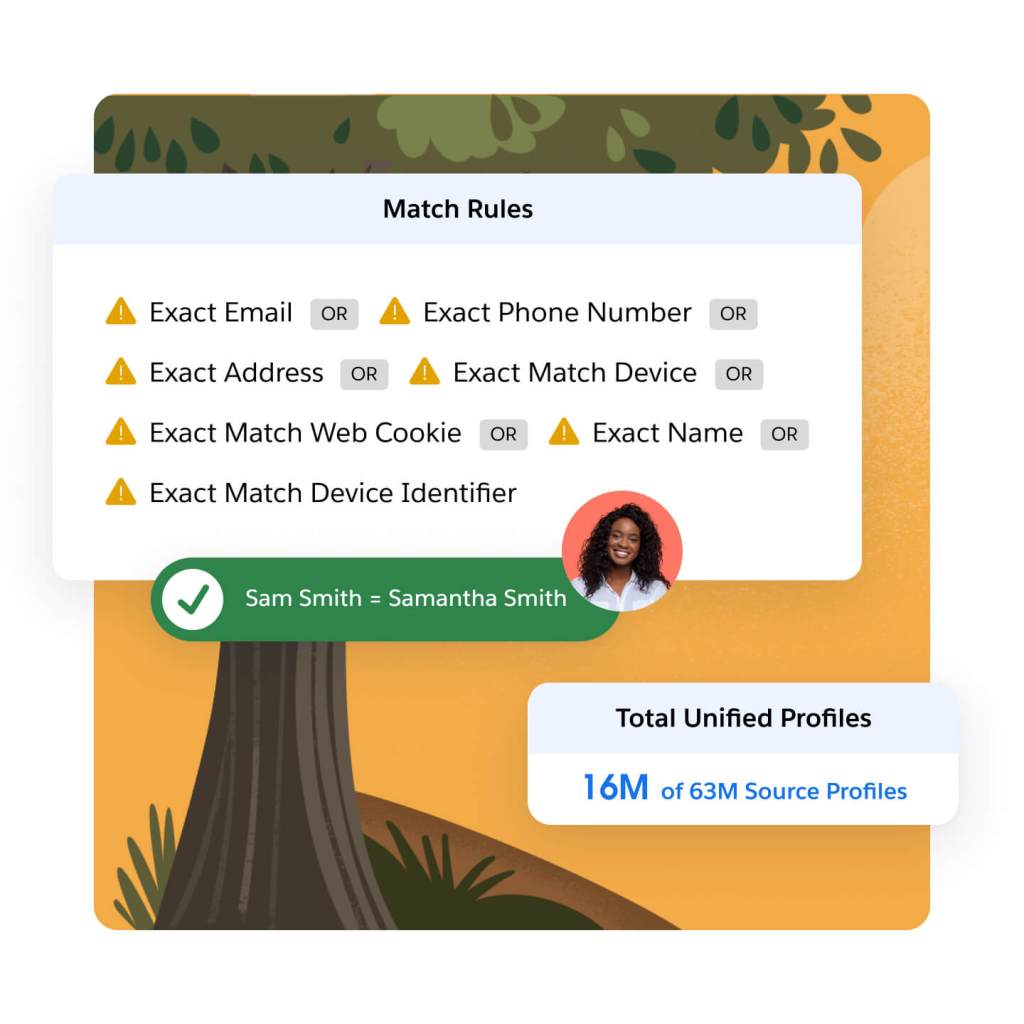
Understand how different types of data (e.g., anonymous, unstructured, real-time) captured in different systems tie back to a single individual. For example, determine that atl@salesforce.com and al123@nto.com are associated with the same person using user-defined rules to link disconnected records together.
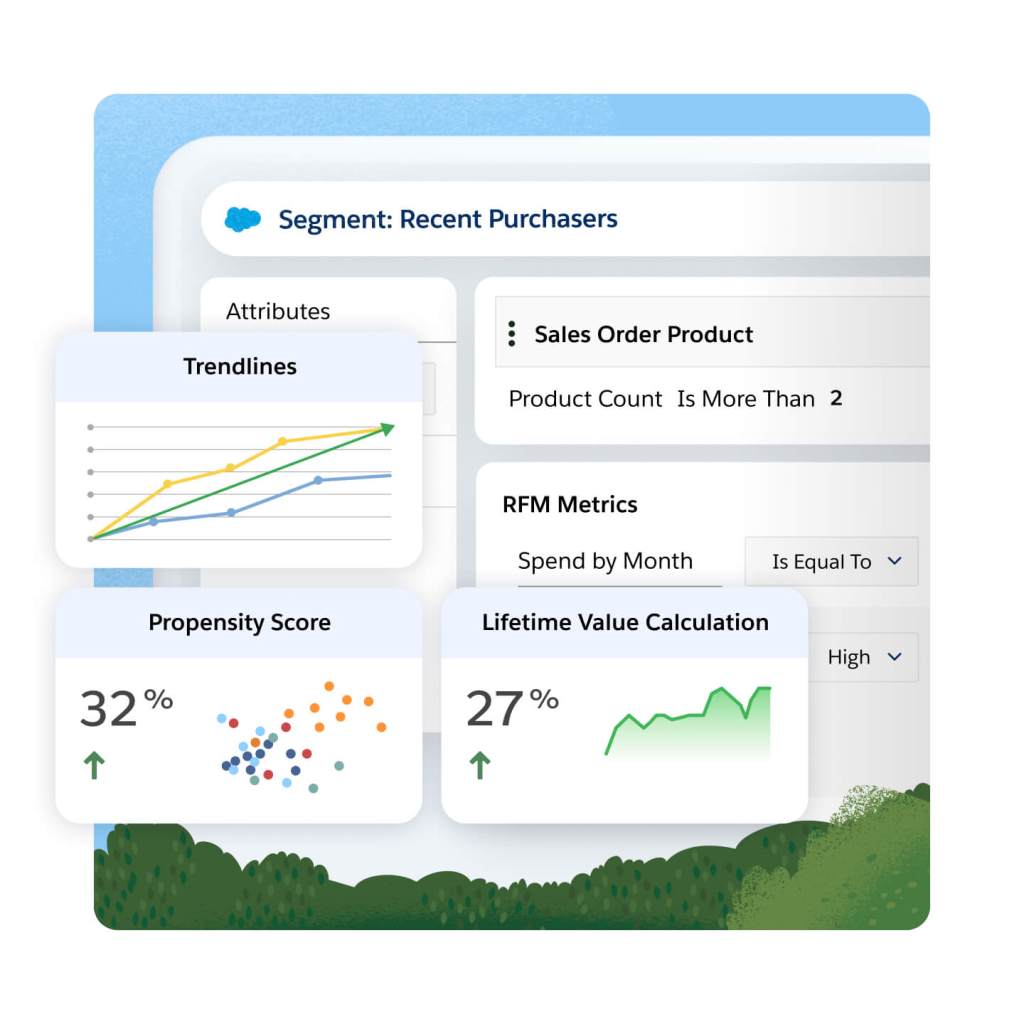
Real-Time Data Access for Marketers
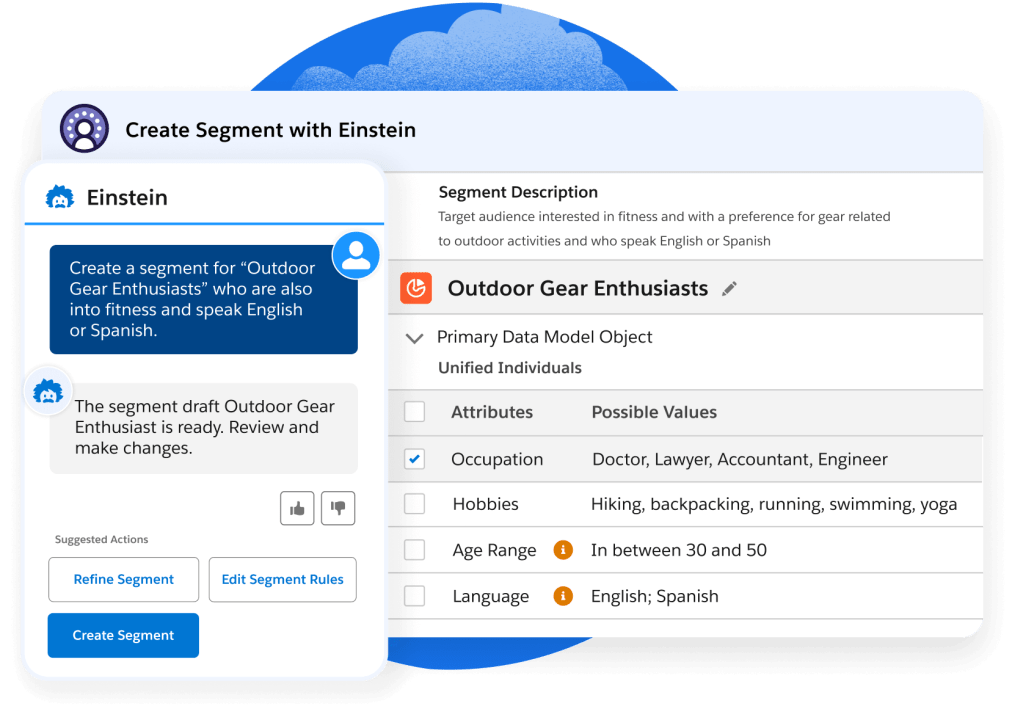
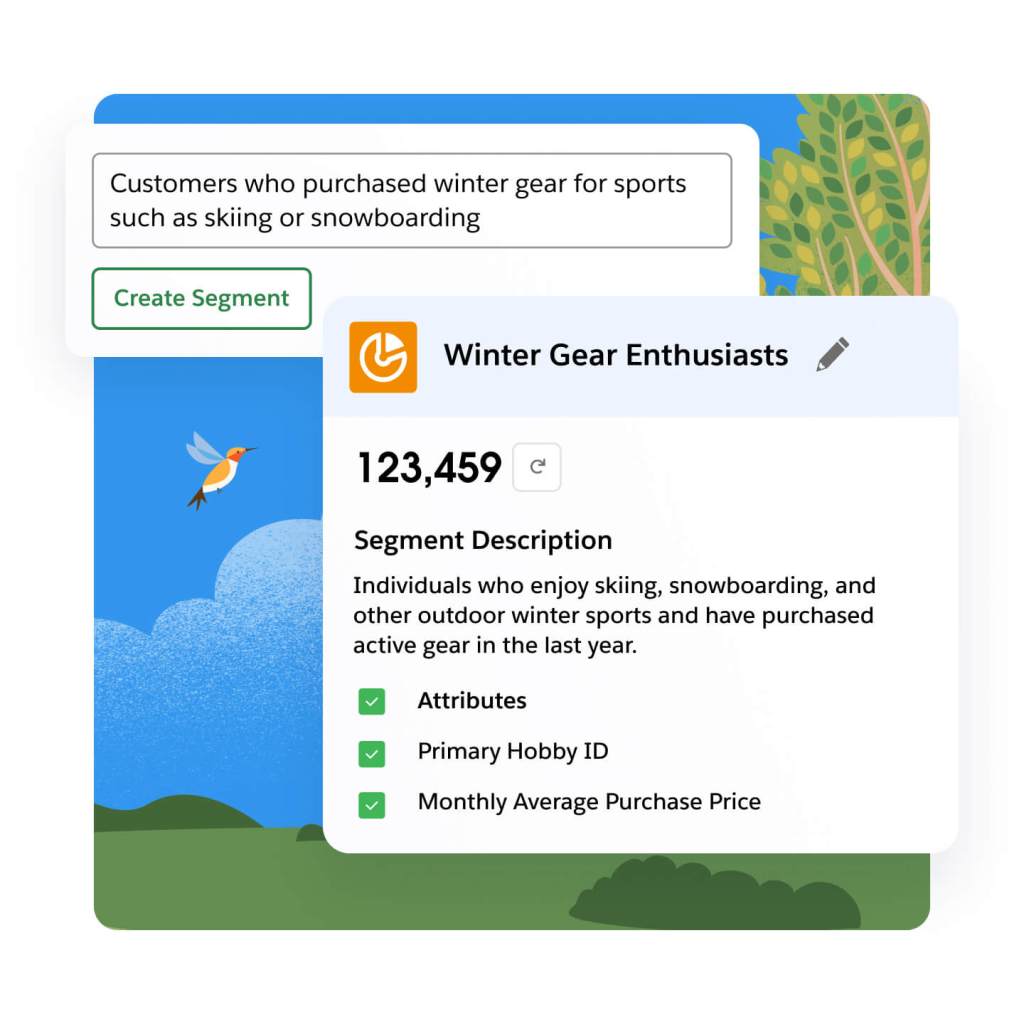
Create targeted audiences faster, without SQL or requesting data, using generative AI to translate plain language descriptions into functional segments in seconds. Use a no-code builder to create and prioritize audiences with Waterfall segmentation to avoid over-marketing. And expand campaign reach by finding new customers like your high-value segments using Einstein Lookalikes.
Embed data from Data Cloud into Marketing Cloud AI without custom integration or manual handoffs to save time, increase productivity, and deliver more relevant content and journeys (e.g., generate email imagery based on past purchases and optimize message send time so the customer receives it when most likely to engage).
Break down barriers between marketing users and data science teams, with direct integrations between Data Cloud and external tools like Amazon SageMaker that allow marketers to consume predictions and scores (e.g., propensity to buy) generated by custom AI/ML models that can inform personalized engagement.

Minimize the number of external analytics tools needed to understand customers and how they respond to campaigns. Use Calculated Insights (e.g., lifetime value) in Data Cloud built with customer profile data and out-of-the box dashboards that combine customer and revenue data to understand and optimize segment performance across activations (e.g., Google Ads campaign).
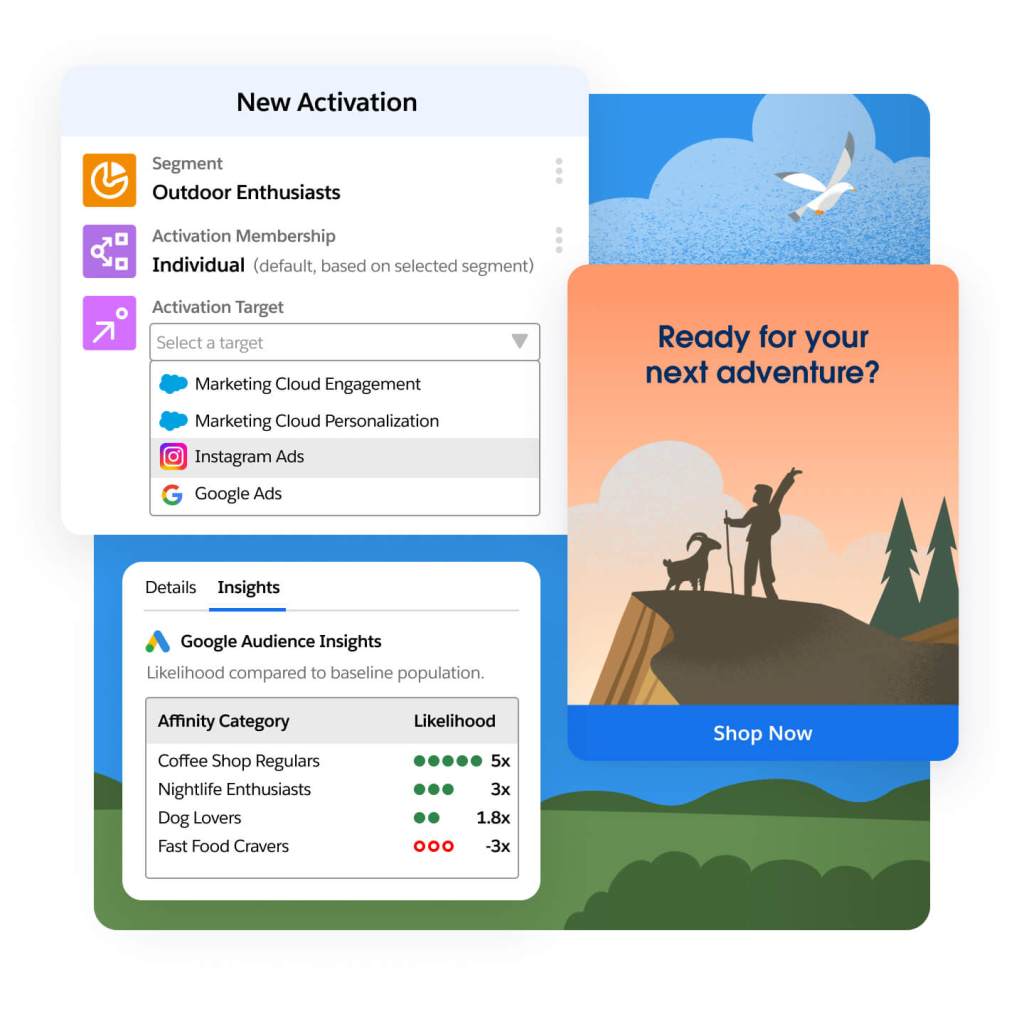
Seamless Activation to Any Channel
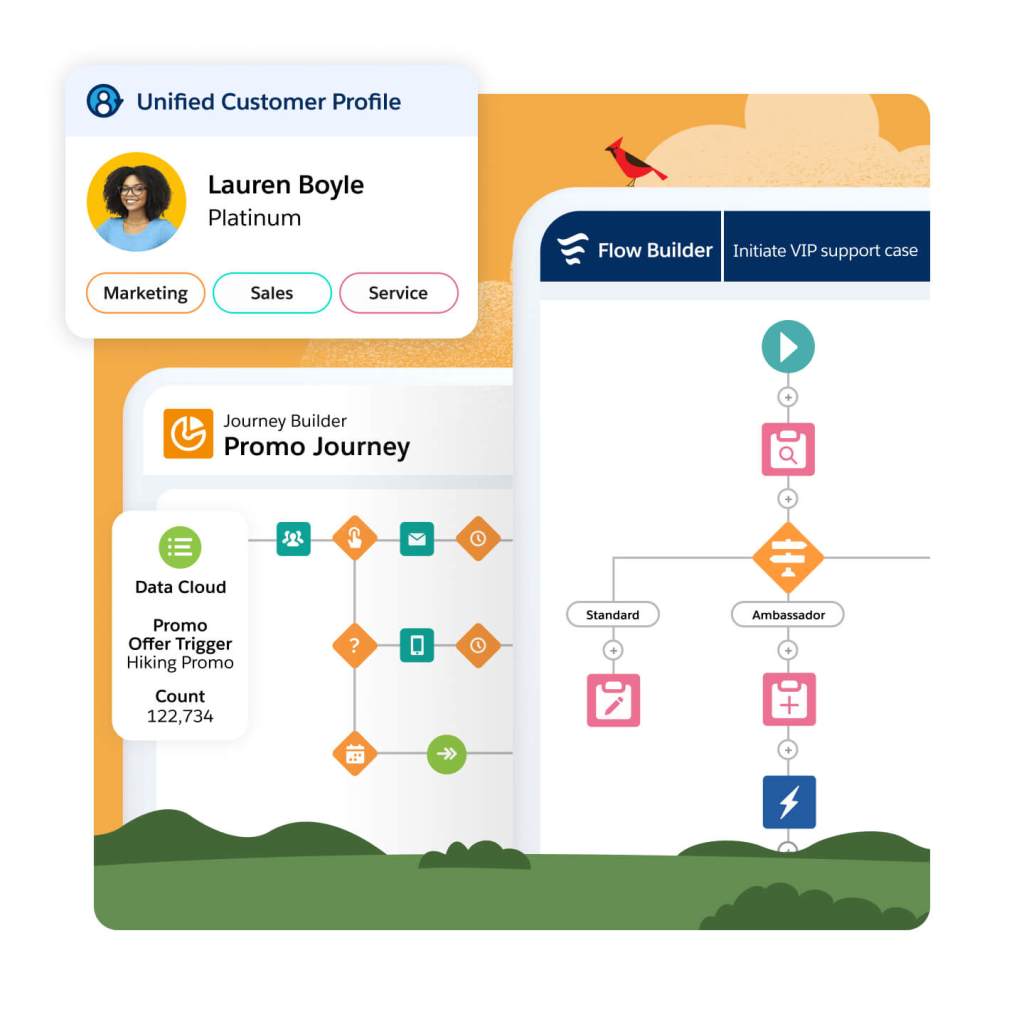
Boost the relevance of AI-powered recommendations and offers based on unified profile data from every engagement with your brand (e.g., show customer personalized product recommendations on web based on browsing behavior, in-store purchases, past service cases, or sales inquiries).
Make every journey touchpoint more relevant and timely, activating Data Cloud audiences with data points that influence channel, content, and frequency (e.g., automatically trigger education journey when customers are not using key product features). Refresh journeys with the most up-to-date data and segment membership as changes occur.
Reduce wasted spend through more relevant advertising campaigns or by suppressing advertising when it’s not the right time, powered by consented data from customers. Reach customers with direct activation integrations to ad partners like Google, Meta, Amazon, and LinkedIn. Enrich profile data and optimize programmatic media buys with apps from AppExchange partners like Acxiom and The Trade Desk.
Bring the operational customer profile into every workflow across the business, with a single platform built on CRM and the same unified data powering alerts to sales reps, personalized ecommerce experiences, next-best-action service recommendations, and more.


Gartner named Salesforce a Leader in Customer Data Platforms. See why.
Extend the power of Data Cloud for Marketing with these related products.
Marketing Cloud Engagement
Create and deliver boundless, personalized customer journeys across marketing, advertising, commerce, and service.
Marketing Cloud Account Engagement
Grow efficiently by aligning marketing and sales on the #1 CRM with marketing automation and account-based marketing.
Marketing Cloud Personalization
Automate dynamic offers for each customer in real time across each moment in the customer journey.
Marketing Cloud Intelligence
Optimize marketing performance and spend across every campaign, channel, and journey with cross-channel analytics and reporting.
Loyalty Management
Nurture relationships and create lasting loyalty on the world’s #1 CRM.
Service Cloud
Personalize support across self-service, your contact center, and the field with AI and real-time data on the #1 CRM.
Sales Cloud
Set the foundation for revenue growth with Salesforce automation and the #1 CRM.
First, choose the right Data Cloud for Marketing edition for your business needs.
Find the right Data Cloud Starter for Marketing edition for your business needs.
Data Cloud for Marketing Pricing
Unify all your data into a single customer profile.
$
108,000
USD/org/year*
(billed annually)
- Data Ingestion and Harmonization
- Identity Resolution and Activation
- Insights and Predictions
This page is provided for informational purposes only and is subject to change. Contact a sales representative for detailed pricing information.
Get the most out of Data Cloud for Marketing with partner apps and experts.








AI, Data, and CRM are how we achieve the promise of speaking directly to consumers with the thing that matters most to them.
Doug MartinChief Brand and Disruptive Growth Officer, General Mills

With Salesforce, we can provide personalized experiences that meet passenger needs - even if they are one in 80 million.
Peter BurnsDirector of Marketing and Digital, Heathrow

Stay up to date on all things marketing.
Sign up for our monthly marketing newsletter to get the latest research, industry insights, and product news delivered straight to your inbox.
Learn new skills with free, guided learning on Trailhead.

Hit the ground running with marketing tips, tricks, and best practices.




Ready to take the next step?
Talk to an expert.
Tell us a bit more so the right person can reach out faster.
Stay up to date.
Get the latest research, industry insights, and product news delivered straight to your inbox.

Data Cloud for Marketing FAQ
Data Cloud for Marketing is a trusted data foundation for your business, built for customer relationships. By harmonizing data that’s updated every millisecond, your teams can meet customers like never before.
Data Cloud is an evolution of our customer data platform (CDP) product, and transcends traditional marketing use cases by funneling a nearly infinite amount of dynamic data to the Customer 360 in real time.
Data Cloud connects, unifies, and activates data to power experiences across the entire customer journey, from marketing to sales, service, commerce, and more.
Data Cloud closes gaps stemming from fragmented data and experiences, helps teams navigate privacy changes and the cookieless future, and boosts productivity through actionable insights and automated engagement.